
1. 摘要
本文提出了一种大数据质量体系建设的方法,能对数据处理过程中的ETL任务进行数据质量监控,并根据监控结果进行必要的告警或任务中止。监控任务的开启可以增量进行,对存在的ETL任务不需要做任何修改,监控任务的开启或关闭也不影响原有的ETL任务的依赖关系。
2. 背景
随着极光各个业务线的业绩发展越来越依赖数据中心所提供的数据分析能力。
数据中心数据平台上运行的ETL任务也越来越多,处理逻辑也越来越发复杂ETL任务的依赖链也越来越长,这些ETL任务往往还是由不同团队的不同业务人员开发的,业务人员的开发水准参差不齐,不同团队之间的沟通也可能不畅,造成ETL任务的数据质量问题频发,更严重的是,出了质量问题后,因为任务的依赖链很长,造成排查数据质量问题困难重重,需上下游一层一层的排查,需不同团队的开发人员协调排查,极大的降低了数据产出效率。
另外,因为没有统一的数据质量监管措施,往往是业务发现数据报表有问题后反馈给开发人员,开发人员才被动的去查找问题,修复错误,缺乏发现问题的主动性。
最后,因为没有统一的数据质量监管措施,往往只会在数据质量问题已经扩散开来以后才会被感知到,造成大量计算资源的浪费和修补过程的耗时。
为了彻底扭转这种局面,一个强大的数据质量监控系统是非常必要的。本文就结合极光的实际情况设计了一套数据质量监控系统,比较完美的解决了上述的问题。
3. 设计方案
极光的数据质量监控平台非常依赖于ETL任务的调度平台提供的底层功能,其整体架构如图3-1所示

图3-1数据质量监控项目后台架构
数据质量服务后台负责的事务主要由:
1. 负责接收前端的配置信息并存入后台数据库;
2. 接受质量检查过程中上报的指标采集,指标评估,任务告警制动等的质量检查过程的跟踪日志;
3. 从调度系统获取调度任务列表及其与质量检查有关的任务配置信息;
图中的调度节点本质上就是调度系统启动的一个调度进程,在正常的调度过程中,调度进程根据配置的任务类型运行相应代码,比如,如果运行的任务是一个hive脚本,则调度进程会通过hive的客户端提交hive脚本给hive服务端来执行该脚本,这里为运行hive脚本所需要的hive客户端代码被统一抽象成一个SideCarProxy组件,提供统一的接口,不同类型的ETL任务通过不同的SideCarProxy实现来提交和运行不同类型的ETL任务,比如Spark任务的SideCarProxy实现就会提供提交spark任务的功能,Spark类型的ETL任务只需负责具体业务逻辑的实现。
为了支持ETL任务开启数据质量检查功能,我们扩展了SideCarProxy的功能,在保持与原来接口兼容的基础上扩展了三种接口,分别是数据质量指标采集接口,数据质量指标评估接口,数据质量检查动作接口和数据质量告警配置接口。这些质量检查接口根据其触发检查的时间点不同可以进一步分为前置检查,中置检查和后置检查。
前置检查是在ETL任务运行前触发的质量检查工作,一般用于检查ETL任务的输入数据是否满足要求;中置检查时在ETL任务运行期间监控任务运行情况的一种检查机制,常常用于任务启动时间,运行时长,完成时间等指标的检查;后置检查是在ETL任务运行完成后触发的质量检查工作,一般用于检查ETL任务的输出数据是否满足要求。
3.1 数据质量指标采集接口
数据质量的检查依赖数据质量检查指标的定义,这种指标的定义完全由业务根据自身的需要定义。为了提供系统的使用便利性,系统内置了一些常用的数据质量检查指标,比如任务的启动时延,运行时长,完成时延。对于业务特定的指标,系统支持通过sparksql的方式来自定义业务特有的数据质量采集指标,如截图3-2所示


图3-2 质量检查的预定义指标和自定义指标
3.2 数据质量指标
利用数据质量指标采集接口,可以实现从数据的时效性,完整性,一致性,统计特征等各个角度来实现数据质量的监控,下面通过示例的方式来说明怎么实现这些指标的监控。
3.2.1 时效性指标监控
时效性指标目前主要是通过任务的启动时延和结束时延来实现,启动时延监控ETL任务配置的启动时间与任务实际的启动时间之间的延迟;结束时延监控ETL任务配置的启动时间与任务实际的完成时间之间延迟;这两个指标监控系统已经原生支持,开发人员只需开启这两个监控项即可
3.2.2 完整性指标监控
完整性指标一般监控目标表的数据是否完整,最简单的检测方式就是统计目标表指定分区的记录数,这种检测目前可以通过系统的自定义指标接口来实现,其实现的SQL逻辑如下表所示
SELECT count(1) AS cnt FROMtarget_table_path WHERE pt_date = '${hivevar:pt_date}' |
表3-1 完整性指标采集的SQL实现
SQL中的变量会自动被任务调度时所引用的具体变量值替换,每次ETL任务运行时该指标都会被检测一次,其检测值在经过评估规则的评估后根据告警规则实现告警动作。后续规划把一些大家常用的完整性指标实现为系统原生支持,提高大家使用的便利性。
3.2.3 一致性指标监控
一致性指标的监控和完整性指标的实现方式完全相同,目前的实现还需要用户编写SQL脚本来实现,后续也规划把常用的一致性指标实现为系统原生支持的方式。
3.2.4 数据统计特征监控
这类指标是完全依赖ETL任务本身的业务逻辑的,本质上是一类数据的业务质量的检测,目前该类指标的监控都需要业务自己通过SQL的方式来表达指标采集逻辑,系统只会提供这些指标的保存和管理功能。下面以监控任务的数据倾斜程度为例来说明这类监控指标的实现,假定数据倾斜以数据分布偏离均匀分布的程度来衡量,则其倾斜指标可以定义为(公式来源于信息论的交叉熵)

SELECT sum(ln(cnt * 1.0/ total)) ASskew_rate FROM ( SELECT key, cnt, sum(cnt) over () AStotal FROM ( SELECT key, count(1) AScnt FROMtarget_table_path WHEREpt_date = '${hivevar:pt_date}' GROUP BYkey ) t ) |
表3-2 数据统计特征指标采集的SQL实现
获取这个倾斜率后根据评估规则中配置的阈值即可检测数据倾斜的程度是否在合理的范围内,并做相应的告警。
3.3 数据质量指标评估接口
数据质量指标评估接口用于评估采集到的数据指标是否符合数据质量要求,其接口主要接受两个参数,分别是评估规则和阈值范围。评估规则决定了采集到的指标值经过怎样的计算才能转换成评估值,阈值范围决定了评估值的合理范围,评估值一旦超出阈值范围,就视为数据质量不合格。
根据业务的需要,可以选择不同的评估规则,为了提高系统的使用便利性,系统内置了透传,同比,环比三个评估规则,业务也可以根据业务的需要通过sparksql自定义评估规则。
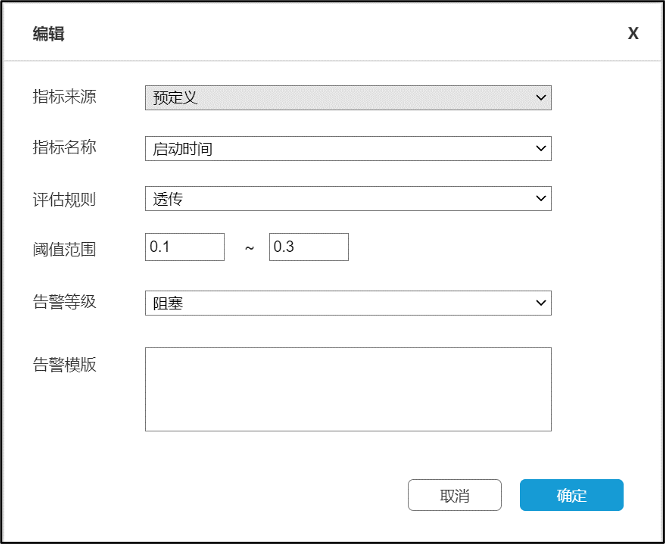
图3-3 质量检查的评估规则与告警设置
3.4 数据质量检查动作接口
数据质量检查动作接口配置数据质量检查不合格时所采取的措施,目前支持忽略,告警和阻塞三种动作。忽悠表示不做任何操作,检查任务和ETL任务正常运行;告警表示根据配置的告警模板通过钉钉,短信或电话的方式发出告警消息,但检查任务和ETL任务都正常继续运行不受影响;阻塞表示根据配置的告警模板通过钉钉,短信或电话的方式发出告警消息,同时该ETL任务及其质量检查任务都终止,ETL任务视为执行失败,依赖该任务的后续任务不能继续执行,此时,需要人工干预修复数据并通过数据质量检查后该任务才视为执行成功。
3.5 数据质量告警配置接口
数据质量告警配置接口主要配置告警的接收人,接受渠道和其他一些与告警有关的一些高级设置
4. 总结
数据质量监控项目为业务数据质量的监控提供了一个统一的平台,使得业务数据的质量保障工作从被动通知提升到了主动发现的水准,并为业务本身参与数据质量保障工作提供的参与手段。
同时,为了进一步提高数据质量的保障工作,数据质量监控项目也在不断给增强和完善,后续规划改善的几个方面主要有:
1.持续提供更多的预定义采集指标,预定义评估指标
2.支持更多的自定义指标的实现方式,比如支持通过python实现自定义指标
3.通过利用ETL任务的依赖血缘关系,能进一步评估数据质量问题的影响范围,根据影响范围给与不同的告警等级,根据影响的业务线提前通知相关业务人员和开发人员做好相关的协调工作。
Previous article:
投其所好的陷阱 —— 数据智能下的用户体验现状Next article:
百亿级数据的实时存取优化与实践






